
A robots.txt file az egyik legegyszerűbb része a weboldaladnak, és alapvetően arra szolgált, hogy kizárjunk webes feltérképező robotokat az oldalunkról. (Robots Exclusion Protocol). Információkat tartalmazhat a keresőmotorok számára arról, hogy a weboldalad mely részeit térképezhetik vagy nem térképezhetik fel. Ezen feltérképezés alapján tudnak majd rangsorolni a tartalmaid.
Mivel tényleg csak egy egyszerű .txt kiterjesztésű file-ról van szó, elsőre nem tűnhet nagy ördöngősségnek a beállítása. Viszont akár egyetlen karakter helytelen használata is súlyos károkat okozhat a SEO-nak. Ezért különösen fontos erre odafigyelni.
Szükséged van-e egyáltalán a robots.txt-re?
Sok weboldal számára, különösen a kisebbek számára, a robots.txt fájl megléte nem kritikus. Mégis jó, ha van, mert többlet kontrollt ad neked a keresőmotorok felett:
- Megakadályozhatja a fejlesztői, vagy egyéb tesztkörnyezet felfedezését.
- Kitilthatóak a belső kereső által generált találati oldalak.
- Takarékoskodhatunk a „crawling budget”-tel.
- Megelőzhető a szerver túlterhelés.
- Privát, szenzitív, vagy duplikált tartalmak kiszűrését is szolgálhatja.
Fontos megjegyezni, hogy bár a például a Google általában tényleg nem indexeli a robots.txt-ben blokkolt tartalmakat, a tiltás megléte erre nem garancia. A Google szerint ugyanis, ha a tartalomra más helyekről is történik hivatkozás valahol az interneten, akkor az a tiltás ellenére még mindig megjelenhet a Google találati eredményei között. Ugyanis a robots.txt-vel nem az indexelésre, hanem a crawling-ra lehet hatni, elsősorban.

Forrás: Google, What is a robots.txt file used for?
Ha már indexelt tartalmat akarunk eltüntetni, a noindex meta robots címkét vagy az X-Robots HTTP fejlécet javasolt használni.
Hol találod a weboldalat robots.txt file-ját?
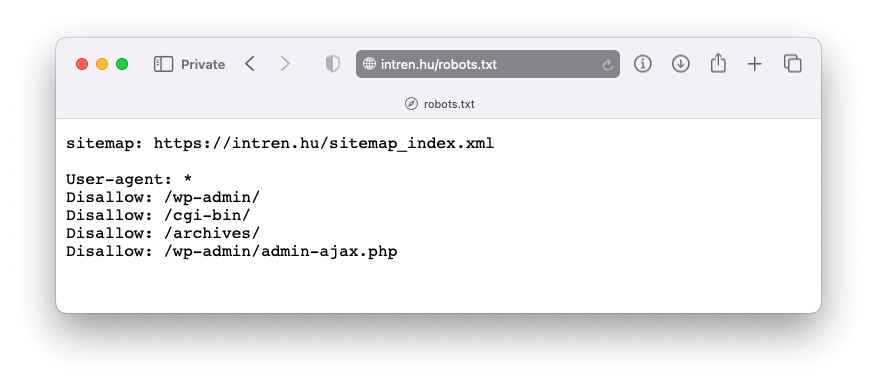
Ha már van robots.txt file a weboldaladon, akkor azt a sajatdomained.hu/robots.txt címen találod. A keresőmotorok is ezen az útvonalon keresik. Nyisd meg a böngésződben ezt az URL-t. A Intrennél ez így néz ki: https://intren.hu/robots.txt

Ha ezen az URL-en nem találod, vagy ha más URL-en van, akkor mindenképpen olvasd tovább a cikket, mert feladatod lesz vele!
FONTOS! Használj külön robots.txt fájlt minden aldomainhez!
A robots.txt csak azzal a domainnel, illetve subdomainnel kapcsolatban irányítja a keresőmotorokat, amelyiken található.
Például, ha a céges blogod a blog.sajatdomained.hu -n található, akkor két robots.txt fájlra lesz szükséged.
- Az egyiket a fő domain gyökérkönyvtárába kell helyezni (sajatdomained.hu/robots.txt)
- A másikat pedig a blog aldomain könyvtárába: (blog.sajatdomained.hu/robots.txt)
Melyik sor mit jelent egy robots.txt-ben?
Ha még sosem láttál ilyen fájlt, első pillantásra talán bonyolultnak tűnhet a tartalma, de a szintaxis igazából egyszerű.
Röviden:
- először azonosítani, megszólítani kell a kereső-, vagy egyéb feltérképező motorokat a felhasználójuk (user-agent) alapján,
- majd rájuk vonatkozóan szabályokat, utasításokat (direktívákat) kell felállítani.
Nézzük meg részletesebben ezt a két komponenst.
User-agent: a keresőmotor azonosítása
A crawler (néha robot, bot, és spider néven is említik) egy általános megnevezés, és bármely olyan szoftverre utalhat, aminek az a feladata, hogy automatikusan felfedezze és bejárja a weboldalakat. A Google fő crawler-je, amit a Google Search használ, a Googlebot névre hallgat.
Minden keresőmotor más és más felhasználóval, úgynevezett user-agent-tel azonosítja a crawler-jét. Egy robots.txt fájlban tömeges vagy egyedi utasításokat állíthatsz be mindegyik ilyen user-agent-hez.
Számos user-agent létezik, de SEO szempontból itt van néhány fontosabb, amivel találkozhatsz:
- Googlebot
- Googlebot-Image
- Googlebot-Mobile
- Googlebot-News
- Googlebot-Video
- Storebot-Google
- AdsBot-Google
- Bingbot
- Slurp (Yahoo)
- Yandex
- Baiduspider
- AhrefsBot
- SemrushBot
- GPTBot
- ChatGPT-User
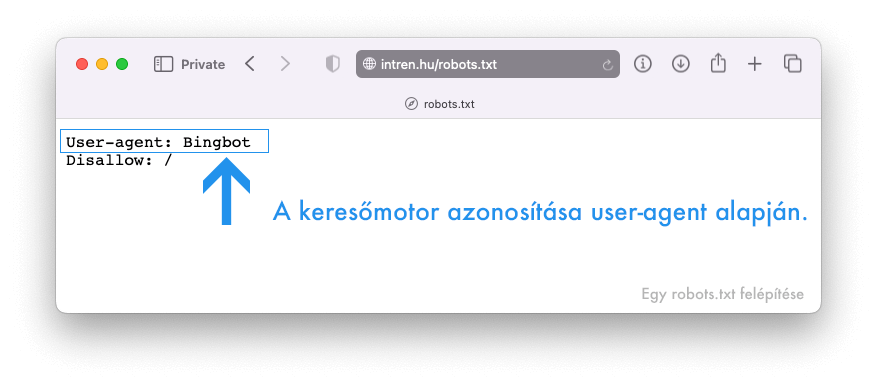
A lényeg tehát: a user-agent megadásával tudod meghatározni, hogy melyik keresőmotorra vonatkozóan állítasz majd fel szabályokat.
Robots.txt utasítások és jelentésük
Az utasítások olyan szabályok (direktívák), amelyeket a megnevezett keresőmotorokkal szeretnénk betartatni.
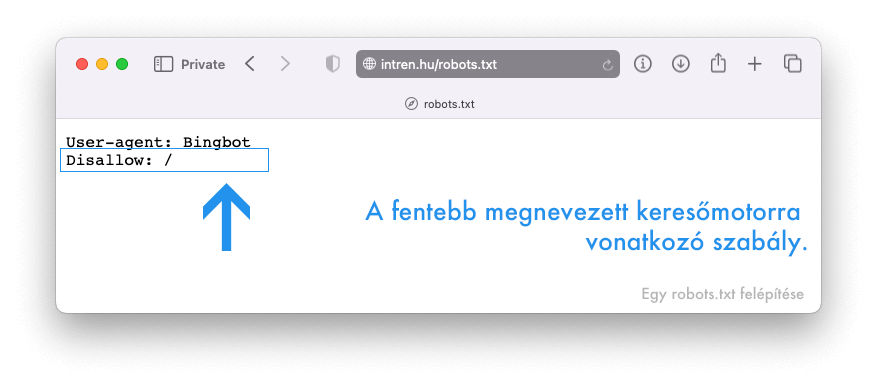
A két leginkább használt ilyen utasítás:
- Disallow – ami a botok kitiltásra szolgál
- Allow – ami a botok beengedésére szolgál
A jelenleg támogatott (és nem támogatott) utasítások egy kicsit részletesebben:
Disallow parancs
Ezt az utasítást használd arra, hogy kitiltsd a keresőmotoroknak. Ezzel érheted el, hogy a kereső botok ne férjenek hozzá a megadott elérési útvonalon található bizonyos fájlokhoz és/vagy aloldalakhoz. De a teljes weboldalra vonatkozó tiltást is ezzel lehet beállítani.
TIPP: Tömegesen is oszthatsz ki szabályokat a csillag jel vagy aszteriszk (*) wildcard karakterrel. Így nem kell megnevezned minden keresőmotort külön-külön.
Tegyük fel, hogy ki szeretnéd tiltani az összes keresőmotort a weboldaladról, kivéve a Bing-et. Így nézne ki a robots file-od:
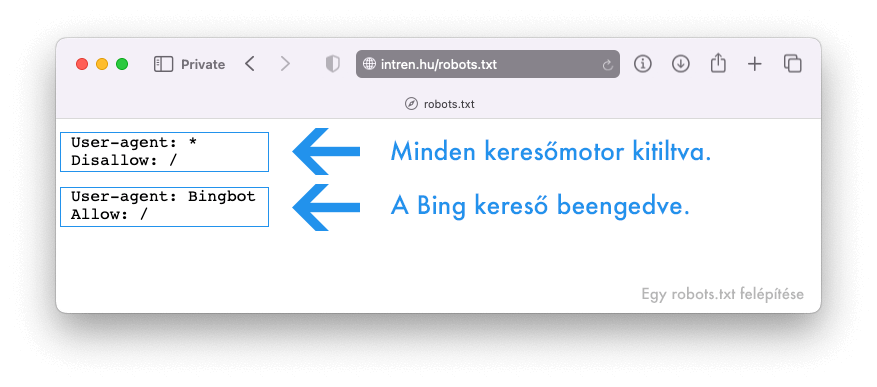
Melyik sor mit jelent?
User-agent: * = A csillaggal megadtad, hogy a következő szabály minden keresőmotorra vonatkozik
Disallow: / = Megtiltottad neki a weboldal bejárását
User-agent: Bingbot = Megadtad, hogy a következő szabály csak a Bing keresőmotorra vonatkozik
Allow: / = Megengedted neki a weboldalad bejárását
A böngészőrobotok csak az őket legegyértelműbben megcélzó deklarációkat követik. Ezért a fenti robots.txt fájl az összes botot blokkolja, kivéve a Binget, mert a Bingbot figyelmen kívül hagyja a rá kevésbé specifikus deklarációt.
Ha azt szeretnéd, hogy egyetlen keresőmotor se crawlolja pl. a blogodat és annak egyetlen bejegyzését se, akkor robots.txt fájlod így nézhet ki:
User-agent: *
Disallow: /blog
Vigyázz! A “Disallow: /blog” sorral minden olyan oldalt kitiltottál, ami “/blog”-al kezdődik. Ha a mappát szeretnéd kitiltani, akkor kell egy “/” (trailing slash) a végére:
User-agent: *
Ha pedig azt szeretnéd, hogy a teljes weboldalad rejtve maradjon minden keresőmotor előtt, a robots.txt fájlod így nézhet ki:
User-agent: *
Disallow: /
Megjegyzés: Ha nem határozol meg elérési útvonalat a „Disallow” utasítás után, a keresőmotorok figyelmen kívül hagyják azt. Vagyis, ha a fenti példából a Disallow után lefelejtjük a “/” -t, akkor az lényegében “Allow”-t jelent majd.
Egy fájlban annyi user-agentnek adhatsz utasításokat, amennyinek csak szeretnél, de az elsőre vonatkozó utasítások nem vonatkoznak a másodikra, harmadikra, negyedikre és így tovább.
Ez alól kivétel, amikor többször is megnevezed ugyanazt a user-agentet. Ilyen esetben az összes releváns, rá vonatkozó utasítást kumulálva kezelik a robotok.
A mesterséges inteligencia és a ChatGPT megjelenését követően webhelytulajdonosként úgy is dönthetsz, hogy ezek crawler-jét tiltod. Robots.txt-ben ezt így teheted meg:
User-agent: GPTBot
Disallow: /
vagy
User-agent: ChatGPT-User
Disallow: /
A kettőből elég egyet használni, mert jelenleg az OpenaAI rendszere mindkét user-agentjét azonosan kezeli, tehát bármelyik letiltása a robots.txt-ben érvényes lesz a másikra is:
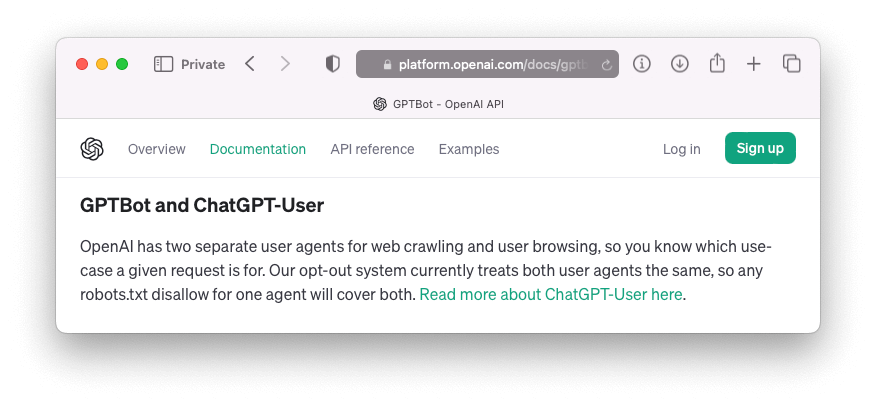
Allow parancs
Ezt az utasítást használd arra, hogy beengedd a keresőmotorokat a weboldaladra, és megengedd nekik, hogy olyan tartalmakat, file-okat is olvasni tudjanak, amelyek egyébként tiltott könyvtárban találhatóak.
A mondat második része fontos részlet. Ugyanis nem kell külön allow paranccsal engedélyezni a keresőmotoroknak az oldalad bejárását. Az ő default álláspontjuk az, hogy
- ha nincs robots.txt file-od, vagy
- ha van robots.txt file-od, de üres, vagy
- ha van robots.txt file-od, de nincs benne disallow tiltás,
… akkor a bejárás alapból engedélyezett.
Ez azt jelenti például, hogy ha csak és kizárólag ennyit tennél a robot.txt-be:
User-agent: *
Allow: /
….annak nem lenne semmilyen pozitív hozadéka. Ugyanezt az eredményt elérheted egy üres vagy hiányzó robots.txt fájllal is.
A fentebbi példánál maradva, ha mondjuk továbbra is azt szeretnéd, hogy a keresők ne férjenek hozzá a blog bejegyzéséhez, kivéve azt/azokat, amiket külön engedélyezel, akkor a robots.txt fájlod így nézhet ki:
User-agent: *
Disallow: /blog
Allow: /blog/ez-egy-jo-tartalom
Allow: /blog/ez-egy-meg-jobb-tartalom
Ebben a példában a keresőmotorok nem férhetnek hozzá a blog mappa alá tartozó egyéb bejegyzésekhez, illetve semmihez, ami “/blog”-al kezdődik. De mivel külön engedélyezve van, elérik csak az a két URL-t, ami Allow direktívát kapott.
Sitemap a robots.txt-ben
Ezt az lehetőséget használd arra, hogy megadd a keresőmotoroknak a sitemap (oldaltérkép) elérési útvonalát.
Itt egy példa erre:
Sitemap: https://intren.hu/sitemap_index.xml
User-agent: *
Disallow:
Érdemes e itt is megadni az oldaltérkép elérését, ha már beküldted azt Search Console-on keresztül? A Google esetében valamelyest felesleges, de remek backup arra az esetre, ha menet közben elveszítjük a Search Console fiókunkat, vagy a hozzáférésünket. Azonban más keresőmotoroknak, például a Bingnek és Yahoonak is segít megtalálni a sitemap-et. Nem is szükséges minden keresőmotor esetében külön sorba felvinni ez.
Sőt, egyszerre több sitemap file-t is megadhatunk egy robots.txt-n belül. Bevált gyakorlat, hogy ezt a file tartalmának a legtetején vagy a legalján helyezzük el. Például:
Sitemap: https://intren.hu/sitemapindex1.xml
Sitemap: https://intren.hu/sitemapindex2.xml
Sitemap: https://intren.hu/sitemapindex3.xml
User-agent: *
Disallow:
Crawl-delay – A Google már nem támogatja
Ezt az utasítást használhatjuk arra, hogy másodpercekben megadva időbeli késleltetést állítsunk be. Ezzel erőforrást spórolhatunk a szerverünknek. Például, ha azt akartuk, hogy a Bingbot csak 5 másodpercenként tudjon elindítani egy lehívást, akkor ez így nézne ki:
User-agent: Bingbot
Crawl-delay: 5
A Google már nem támogatja ezt az utasítást, de egyéb keresők és crawlerek igen.
Ha mondjuk azt észleljük, hogy a kínai Baidu és a SEMrush nevű online marketinges eszköz megterhelik a szerverünket, de nem akarjuk őket teljesen kitiltani, akkor így állítanánk be a robots.txt-t:
Sitemap: https://intren.hu/sitemap_index.xml
User-agent: Baiduspider
Crawl-delay: 10
User-agent: SemrushBot
Crawl-delay: 10
Mindegyik robotnak 10 másodpercenként engedélyezünk egy requestet. De eltérő értékeket is megadhatunk. Találkoztunk már olyan esettel is, hogy a világhálót pásztázó, ezekhez hasonló botok olyan mértékben terhelték egyidőben a weboldalt, hogy a tárhelyet szolgáltató szerver felmondta a szolgálatot.
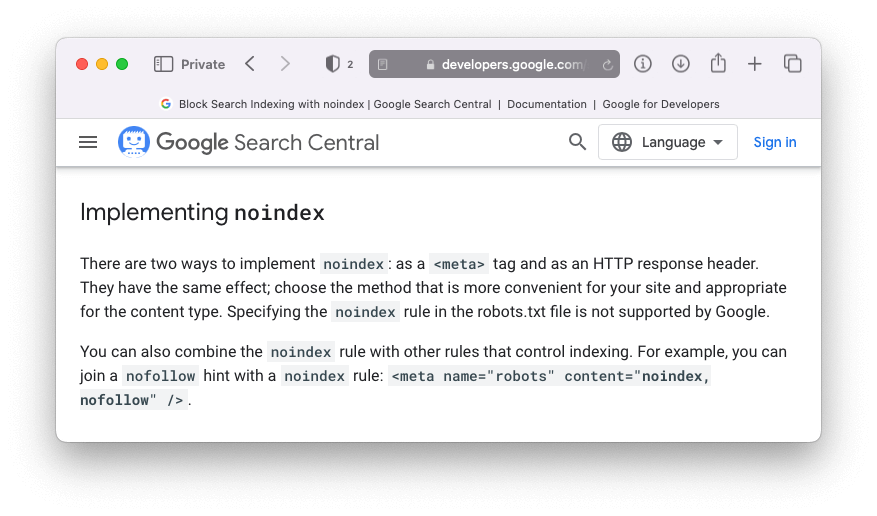
Noindex – A Google már nem támogatja
A Google egyértelművé tette, hogy ezt az utasítást a bot-ja nem veszi figyelembe..
User-agent: Googlebot
Noindex: /blog/
Ha ki szeretnél zárni egy oldalt vagy fájlt a keresőmotorokból, használj inkább noindex meta robots címkét vagy az X-Robots HTTP fejlécet.
Nofollow – A Google nem támogatja
Ez egy másik utasítás, amit a Google sosem támogatott hivatalosan.
User-agent: Googlebot
Nofollow: /blog/
Ha azt szeretnéd elérni, hogy a Google ne kövesse a linkeket az oldalon, használd a rel=”nofollow” link attribútumot.
Speciális karakterek robots.txt-ben
„#” – Hashtag használata megjegyzések és magyarázatok írásához
A keresőrobotok figyelmen kívül hagyják azokat a sorokat, amelyek #-el kezdődnek a robots.txt-ben. Így megjegyzéseket, kommenteket tudunk beleríni. Ez nekünk is és az utódunknak is nagy segítség lehet a későbbiekben.
User-agent: *
Disallow: /
# Csak a Bing-re vonatkozó utasítások KEZDETE
User-agent: Bingbot
Allow: /
# Csak a Bing-re vonatkozó utasítások VEGE
„✱” – Csillag helyettesítő karakter
Fentebb már láttunk példát a ✱ használatára, amikor is több keresőmotort egyszerre tudtunk meghivatkozni vele:
User-agent: *
Ebben az esetben a csillag azt jelenti: minden vagy bármelyik keresőmotor.
Ez a ✱ egy helyettesítő (wildcart) karakter, és bármilyen mennyiségű karakterszámot jelethet.
Elhelyezhető egy URL path elején vagy közepén valahol.
Használhatjuk arra is például, hogy olyan URL-eket tiltsunk le tömegesen, amik paramétereket, vagy valamilyen egyéb jellemző, könnyen beazonosítható és közös információt tartalmaznak, amire hivatkozhatunk, de nem akarjuk manuálisan mindet egyenként felvenni a kitiltottak listájára.
Tegyük fel, hogy az összes jogi nyilatkozatunk nincs egyetlen mappába gyűjtve, de mindegyik URL-je tartalmazz a “-jog-” karaktereket valahol a slug-ban, és ezekre nem akarjuk feleslegesen ráengedni a keresőket. Akkor így nézne ki a tiltásunk:
User-agent: *
Disallow: /*-jog-*
Vagyis disallow minden olyan URL, amiben benne van a “-jog-”, függetlenül attól, hogy előtte vagy utána hány és milyen egyéb karakter található.
„$” jel (dollárjel) az URL végének meghatározásához
Ez kiterjesztés (file tipus) alapján segít a direktívák felállításában. Akkor használd például, ha meg akarod akadályozni, hogy a keresőmotorok hozzáférjenek egy bizonyos file típushoz.
Ha mondjuk az összes .xml file-t akarnád letiltani, akkor a robots.txt fájlod így nézhet ki:
User-agent: *
Disallow: /*.xml$
Ebben a példában a keresőmotorok nem férhetnek hozzá olyan URL-ekhez, amelyek „.xml” -el végződnek (.xml$), függetlenül attól, hogy a file-ok nevei hány karakterből állnak (/*)
“/” (per vagy trailing slash) használata mappák esetében
A lenti robots.txt fájl megakadályozza a keresőmotorokat abban, hogy hozzáférjenek a /blog almappához és minden benne lévő tartalomhoz:
User-agent: *
Disallow: /blog
De ugyanakkor megakadályozza a keresőket abban is, hogy a /blog kezdetű bármely oldal vagy fájlt bejárják.
Például:
/blog-motorok-osszehasonlitasa/
/blog-iroink.html
/blog-otletek.pdf
Ha ezt nem szeretnéd, a megoldás egyszerű: adj hozzá egy perjelt a végéhez:
User-agent: *
Disallow: /blog/
FONTOS! Bármilyen URL-re is hivatkozunk a robots file-ban, az elején mindig ott kell legyen a “/”!
Példa robots.txt parancsok
Íme néhány példa a leggyakrabban használt robots.txt beállításokról.
| Teljes hozzáférés minden kereső számára. | User-agent: *Disallow: |
| Az összes kereső teljes kitiltása | User-agent: *Disallow: / |
| Az összes kereső teljes kitiltása, kivéve egyet (Google) | User-agent: GoogleDisallow:User-agent: *Disallow: / |
| Minden paraméterezett URL letiltása | User-agent: *Disallow: /*? |
| Egyetlen file letiltása minden robot számára | User-agent: *Disallow: /file-neve.pdf |
| Egyetlen file típus letiltása minden robot számára | User-agent: *Disallow: /*.pdf$ |
| Egyetlen mappa letiltása minden kereső számára | User-agent: *Disallow: /mappa-neve/ |
| Egyetlen mappa letiltása minden kereső számára, egy benne lévő oldal engedélyezésével | User-agent: *Disallow: /mappa/Allow: /mappa/oldal-neve.html |
Mégtöbb példát találhatsz itt.
A legtöbb és legnépszerűbb keresők bot-jai (Google, Bing, Yahoo) végre is hajtják a robots.txt-ben talált utasításokat. De jó tudni, hogy néhány crawler teljesen figyelmen kívül is hagyhatja, amit beleírsz. Jogilag ugyanis nincsen arra vonatkozó kötelezettségük, hogy eleget tegyenek a robots.txt-ben megadott kéréseknek.
Hogyan készíts magadnak robots.txt file-t?
Manuálisam: létrehozol egy üres txt file-t, elmented robots.txt néven, beleírod a szükséges utasításokat, és feltöltöd FTP csatlakozáson keresztül a szerverre.
Online generátorral: a manuális módszer helyett használhatsz olyan robots.txt generátort is, mint például ez:
Az ilyen eszközök előnye, hogy minimalizálják a hibákat. Az általa létrehozott file-t ugyanúgy fel kell majd tölteni a weboldalad szerverére.
Hogyan tesztelheted robots.txt file-t?
Ha létrehoztad a file-t, érdemes tesztelni is.
Update: a Robots.txt tester-t 2023.11.15-én lekapcsolta a Google. A lentebbi megoldás már nem működik. A további lehetőségekről lásd a következő alcímet.
A Google két lehetőséget kínál erre: a nyílt forráskódú robots.txt Github könyvtárát és a robots.txt tesztelő eszközét Search Console-on belül. Mivel az első lehetőség inkább haladó fejlesztőknek szól, használjuk a a Search Console adta felületet:
Értelemszerüen a teszteléshez be kell legyen állítania egy Search Console fiók.
Ezen a linken kattintsunk „Robots.txt tesztelő megnyitása” gombra.
TIPP: Amennyiben nem talál a weboldaladhoz rendelt robots.txt-t, a szövegszerkesztő mező üres lesz. Ez egy másik lehetőség a file létrehozására. Másold vagy írd bele a kívánt beállításokat, teszteldt, töltsd le a txt file-t, majd tedd fel a szerveredre.
A tesztelő azonosítja a szintaktikai vagy a logikai hibákat az aktuálisan elérhető robots.txt-ben. Ennek a tartalmát meg is jeleníti:
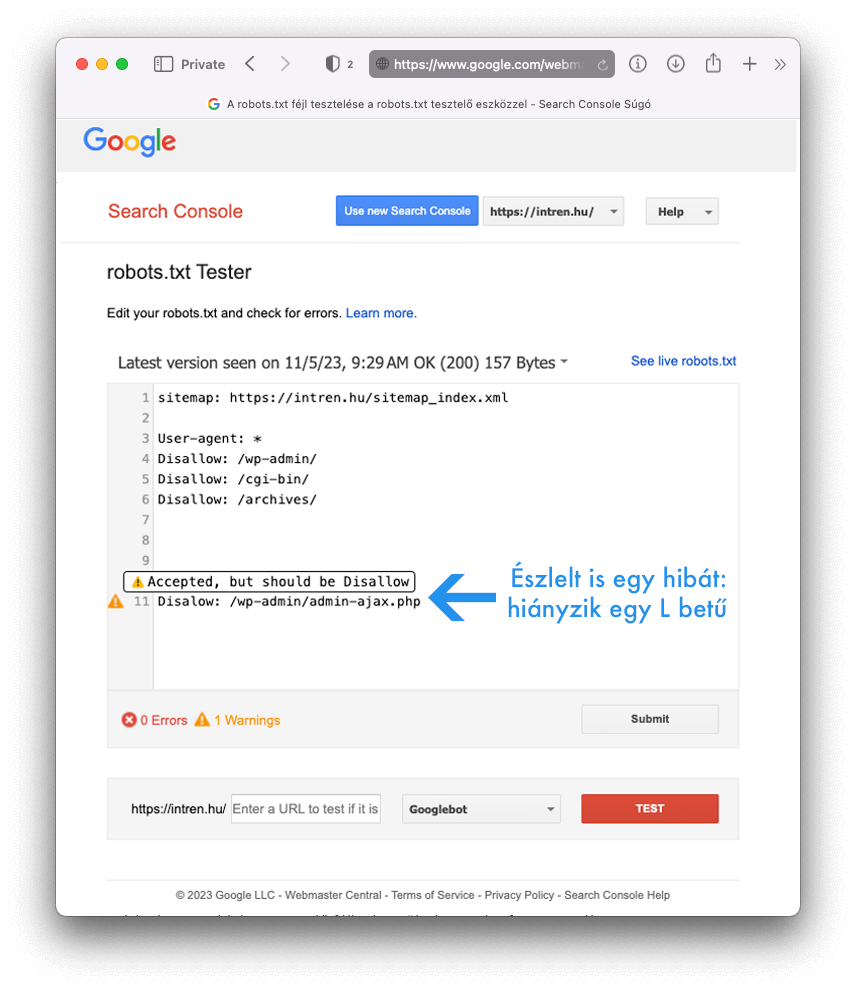
A konkrét hibákat pedig a bal oldalon megjelenő sárga felkiáltójelre vagy piros x-re húzva az egeret tudjuk elolvasni. A mi esetünkben hiányzik még egy “L” betű a Disallow-ból.
A hibás sorokat közvetlenül ezen a felületen javíthatjuk is, majd újra tesztelhetjük.
Fontos azonban, hogy az itt végzett módosítások nem kerülnek elmentésre az tényleges robots.txt-ben. Az eszköz nem változtatja meg a tényleges fájl tartalmát a szerverünkön.
A javított változatot innen viszont le tudjuk tölteni, majd felmásolni a saját webhelyünkre:
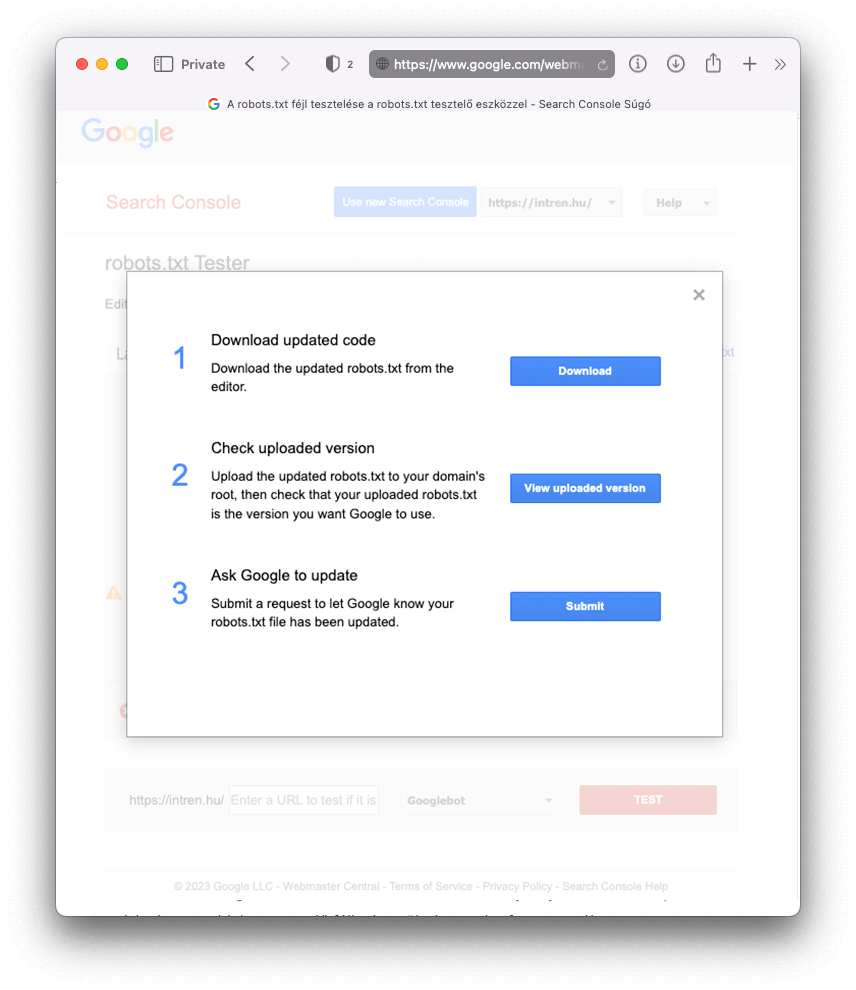
Végül pedig a Submit gombbal tájékoztassuk a Google-t, hogy változott a robots.txt tartalma.
A tesztelés jó dolog, mert egyetlen hiba is súlyos SEO katasztrófát okozhat a weboldaladon – tehát érdemes óvatosan eljárni.
Frissítés 2023.11.15: a Robots.txt tester-t lekapcsolta a Google
A fentebb említett ”Robots.txt tesztelő” eszközt a Google megszüntette.
Helyette bevezetett egy új robots.txt jelentést a Google Search Console-on belül (Settings > robots.txt).
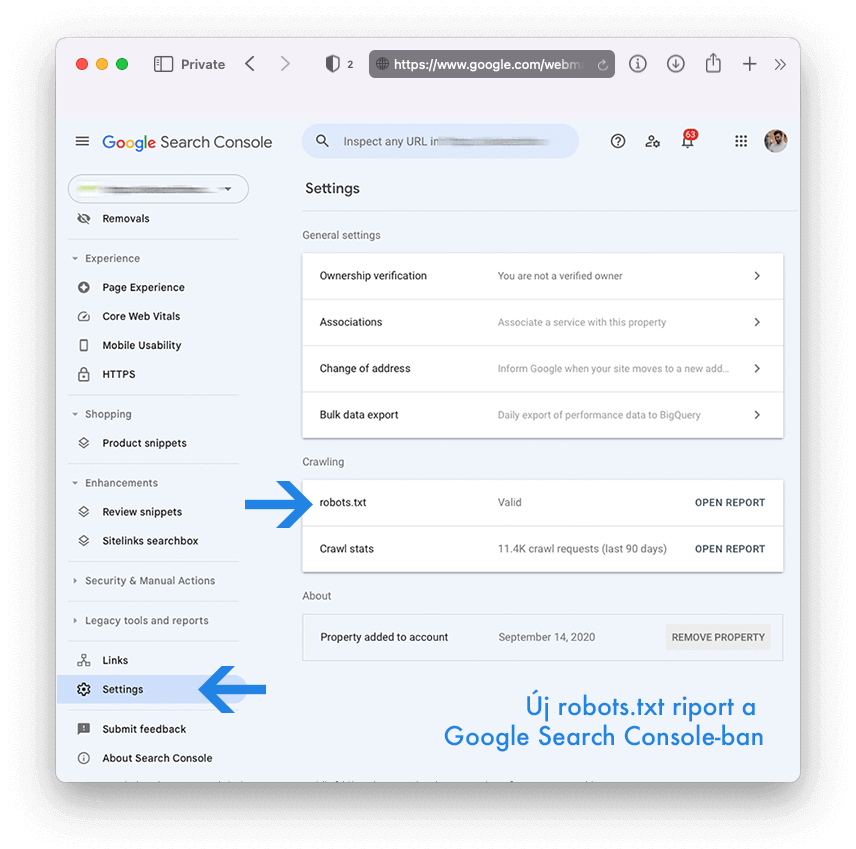 Ezt a jelentést csak olyan robots.txt fájlokhoz használhatjuk, amelyek már elérhetők weboldalunkon. Tehát tesztelésre nem igazán alkalmas. Kár, mert erre az elődje tökéletesen alkalmas volt. Alternatívának pedig csak egy Google keresést találunk a hivatalos dokumentációban: https://www.google.com/search?q=robots.txt+validator – elegáns megoldás 🙂
Ezt a jelentést csak olyan robots.txt fájlokhoz használhatjuk, amelyek már elérhetők weboldalunkon. Tehát tesztelésre nem igazán alkalmas. Kár, mert erre az elődje tökéletesen alkalmas volt. Alternatívának pedig csak egy Google keresést találunk a hivatalos dokumentációban: https://www.google.com/search?q=robots.txt+validator – elegáns megoldás 🙂
Az új riport a következőket tudja:
- Időközönként ellenőrzi, hogy létezik robots.txt file
- Jelzi a lekérés állapotát, ami lehet
- Nem lett lekérve – Nem található (404)
- Nem lett lekérve – Bármilyen más ok
- Lekérve – létezik, látja a Google
- Mutatja az ellenőrzés időpontját
- A lekért fájl méretét byte-ban
- Problémákat, figyelmeztetések: milyen hibákat talált a file-ban
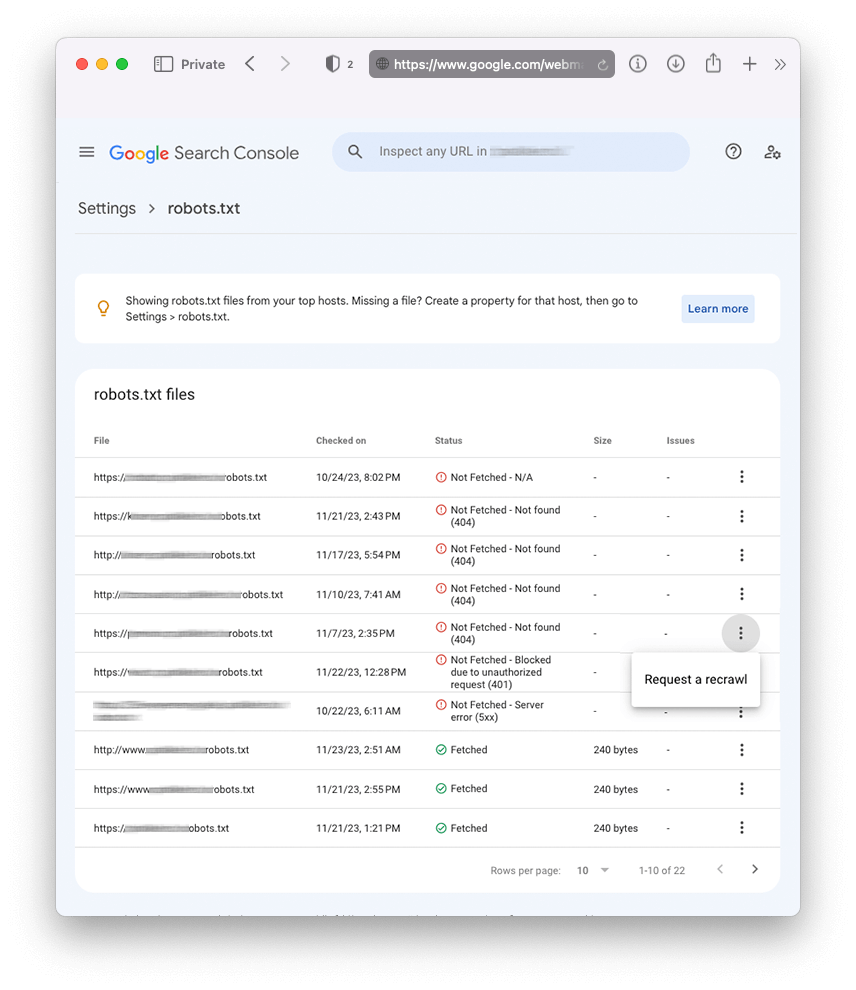
Egyik előnye a riportnak, hogy amennyiben domain property van bekötve Search Console-ba, egy helyen láthatod a domain név és a hozzá tartozó aldomainek robots file-jait (ahogy a fenti képernyőmentésen is látható).
Előnye még az új felületnek, hogy változása esetén (ha javítottál a robots.txt tartalmán), elindíthatod a file újbóli feltérképezését, azonnal jelezve Google-nek, hogy változás történt.
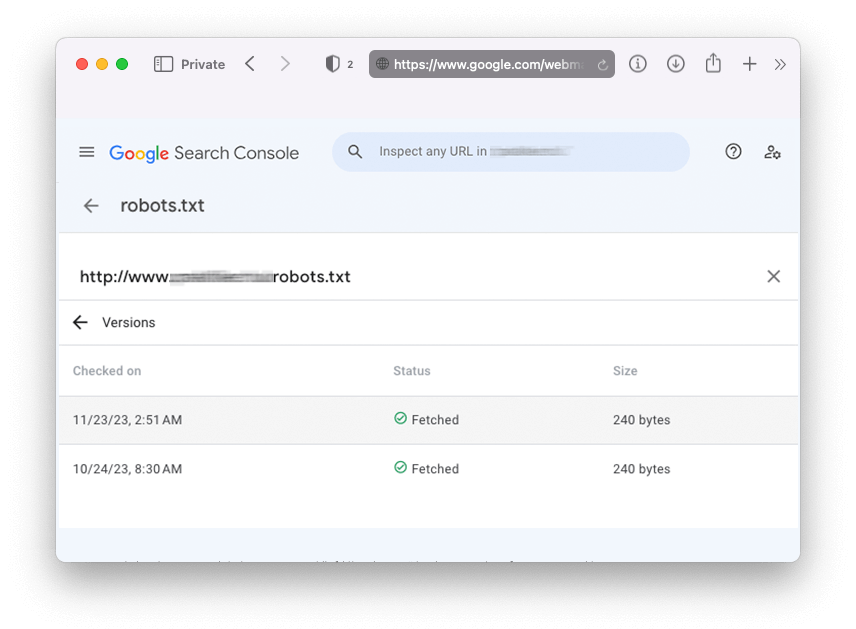
Ami talán a leghasznosabb ebbez az új riportban, az az, hogy lehetőséget ad visszanézni a robots.txt előző tartalmait az elmúlt 30 napból. Ez egyfajta verziókövetésnek is remek lehetőség, így nyomon tudjuk követni, hogy mi mikor változott a mostani állapothoz képest.
Az új jelentés részletes leírását itt találod, de természetesen, mi is állunk rendelkezésre, ha szakértői segítségre van szükséged a te robots.txt-d beállításában.