
Az oldal indexelhetősége azt jelenti, hogy a weboldal tartalmát a keresőmotorok (például a Google) el tudják érni, feltérképezni és szerepeltetni tudják a keresési találatok között. Ha egy oldal indexelhető, akkor a keresőmotorok adatbázisába kerül, és megjelenhet a keresési találatokban, amikor a felhasználók releváns kifejezésekre keresnek. Az indexelhetőség szempontjából fontos, hogy az oldal feltérképezését ne akadályozzák technikai problémák, és egyedi, minőségi tartalom legyen rajta.
Alább megmutatjuk, hogyan néz ki ez a Google Search Console alapján, az egyes hibák mit jelentenek, valamint konkrét példákkal illusztráljuk, hogyan lehet ezt akár URL szinten is lekérni a ScreamingFrog segítségével..
Mit láthatunk a Google Search Console Oldalindexelési jelentésében?
A Google Search Console Oldalindexelési jelentése betekintést nyújt abba, hogy a webhelyünk oldalait hogyan kezeli a Google. Láthatjuk, hogy mely oldalak lettek indexelve, valamint a nem indexelt oldalaknál az esetleges problémák okait is megtalálhatjuk. Az eszköz segít azonosítani azokat az oldalakat, amelyeket a Google nem tud indexelni, és így javítási lehetőségeket kínál. Sok esetben azonban szándékosan tiltunk ki oldalakat a keresőből, így ezek nem feltétlenül jelentenek problémát.
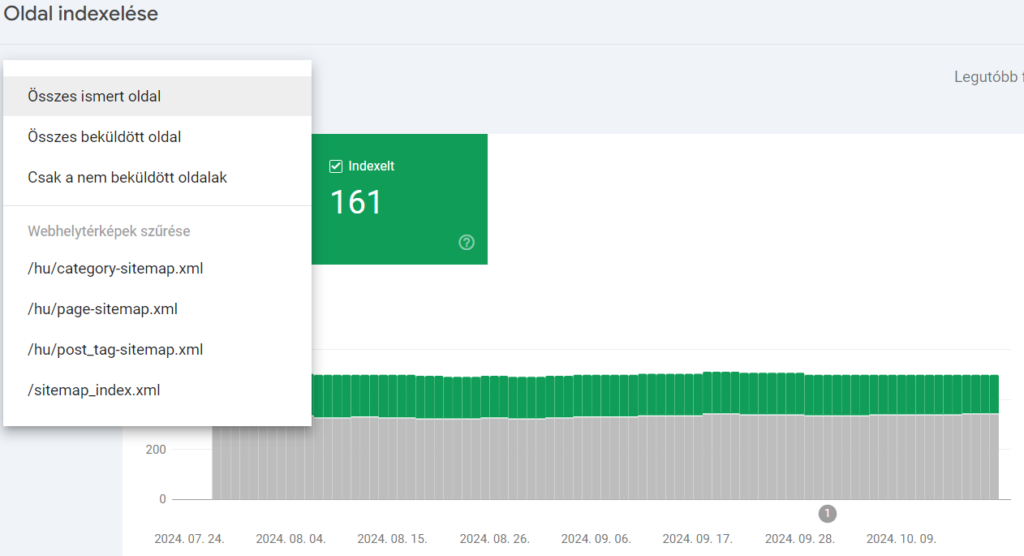
Amennyiben nem a teljes weboldalt akarjuk vizsgálni, leszűrhetjük akár 1-1 oldaltérképre is a vizsgálatot.
Miért nem indexelt egy oldal?
A Google a következő okokat sorolhatja fel az Oldalindexelési jelentésben:

Szerverhiba (5xx):
A szerver valamilyen probléma miatt nem tudott válaszolni a Google kérésére, ezért nem sikerült indexelni az oldalt. Ez egy olyan szerver oldali hiba, aminek fontos, hogy utána nézzenek a fejlesztők, mert ha sok ilyen aloldal van, az árthat az egész Domainre nézve.
Átirányítási hiba:
Az oldal átirányítása nem működik megfelelően, ami akadályozza az indexelést (pl. végtelen átirányítási hurkok). Ezek szintén ártanak az indexálásnak, sőt a sokszoros átirányítás miatt ha végül be is töltődik az oldal, nagyon sok lehet a várakozási idő, valamint sok felesleges URL-t is meg kell vizsgálnia a keresőknek, amely viszi azok forrásait.
Az URL-t a robots.txt letiltotta:
A robots.txt fájlban szereplő szabályok tiltják az oldal feltérképezését, így a Google nem tudja indexelni azt. Sok esetben szándékosan tiltunk ki oldalakat (ilyen lehet a belső kereső, admin felület), amely számos szenzitív, esetleg értéktelen oldalak kitiltását jelenti. Így a keresőnek elég a fontosabb oldalakat betérképeznie, így javíthatjuk a Domain megítélését is a keresők számára. Azonban érdemes időnként felülvizsgálni, mert egy hibával akár a teljes weboldalt kitilthatjuk a keresőből. Számos ilyennel találkoztunk, különösen egy weboldal csere után bennefelejtett tiltással.
Kizárva egy „noindex” címke miatt:
Az oldal fejléce „noindex” címkét tartalmaz, amely utasítja a keresőket, hogy ne indexelje az oldalt. Ez erősebb tiltást jelent, mint a robots.txt. Sok olyan oldal van, amit nem akarunk hogy bekerüljön a keresők indexébe, így a head részben elhelyezett noindex-el tilthatjuk ki őket.
Ha később mégis indexelni akarunk egy ilyen oldalt, akkor első lépésként ki kell venni a noindex részt a kódból, majd erősen ajánlatos a Console-ban felülvizsgálatot kérni. Ugyanis ezeket az aloldalakat sokkal ritkábban vizsgálják meg a keresők.
Lágy 404-es hiba:
Az oldal úgy néz ki, mintha nem létezne (404-es hiba), de a szerver nem adott vissza hivatalos 404-es státuszkódot. Sok oldalnál tapasztaltuk, hogy bár az adott aloldal megszünt, a felhasználóknak 404-es válaszkódot ad, de a keresők számára még mindig 200-as, „OK” válaszkód jelenik meg, mintha továbbra is létezne az aloldal. Ez nem jó sem a keresőknek, sem a felhasználóknak, mert nem nyújt jó felhasználói élményt, ha a keresőből 404-es oldalra kerülünk.
Jogosulatlan kérelem miatt letiltva (401):
Az oldalhoz való hozzáféréshez bejelentkezés szükséges, és a Google nem tud bejelentkezni, ezért nem tudja indexelni. Egy készülő oldal esetében, vagy az admin felülethez ne is férjen hozzá a kereső.
Nem található (404):
Az oldal nem létezik, így a Google nem tudja indexelni.
Tiltott hozzáférés miatt letiltva (403):
Az oldalhoz való hozzáférés korlátozott, ezért a Google nem fér hozzá, és nem tudja indexelni. Hasonló a 401-hez.
Az URL más 4xx hiba miatt letiltva:
Az oldal valamilyen egyéb kliensoldali hibát adott vissza, ezért nem sikerült indexelni. Pl. 410-es válaszkóddal általában adok-veszek oldalaknál lehet vele találkozni (pl. hasznaltauto.hu). Ha már eladtak egy autót, utána az oldal 410-es válaszkódot ad a keresőnek, ami azt jelzi, hogy az adott oldal véglegesen megszűnt.
Alternatív oldal megfelelő kanonikus címkével:
Az oldal egy másik oldal kanonikus verziójaként van megjelölve, ezért az eredeti oldalt indexeli a Google. Gondoljunk csak arra, hogy ugyanaz az oldal elérhető paraméteresen és anélkül is. Példa:
- https://intren.hu/szolgaltatasok/webanalitika/google-analytics-360/?utm_source=facebook
- https://intren.hu/szolgaltatasok/webanalitika/google-analytics-360/
Ha nem használnánk a kódban kanonikus taget, vagy nem megfelelően, akkor mind a 2 URL indexelhető lenne. De mivel pontosan ugyanaz a tartalom, így ez duplikációt okoz. Jelen esetben a kanonikus címke a paraméter nélküli verzióra mutat, így a keresők tudni fogják, hogy az lesz az alapértelmezett, azt kell indexelni.
Párhuzamos oldal, felhasználó által választott gyűjtőoldal nélkül:
Az oldal egy másik, hasonló tartalommal rendelkező oldaltól függ, de a kanonikus címke nincs megfelelően beállítva.
A fenti példánál maradva, ha nem lenne kanonikus címke az oldalban, akkor a keresőre lenne bízva, hogy melyik változatot indexeli. Mivel a kereső érzékeli, hogy itt duplikáció van, így amelyiket nem indexelte, az jelenik meg ebben a listában.
Párhuzamos oldal; a Google a felhasználó által megjelölt gyűjtőoldaltól eltérőt választott:
Az oldal kanonikus címkéje eltér attól, amit a Google kanonikusnak tekint, így nem ezt az oldalt indexeli.
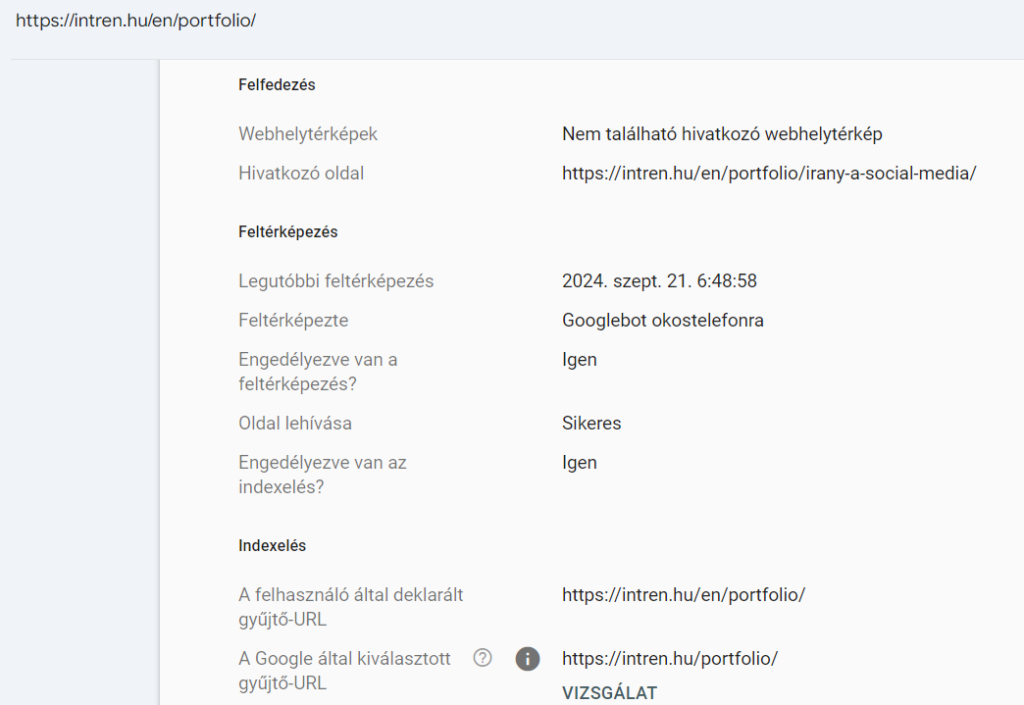
Előfordul, hogy a Google egy másik aloldalt értékesebbnek gondol, mint amit mi megadtunk a kanonikus címkében. Pl. lehet, hogy sokkal több hivatkozás van a másik verzióra. Így itt ezeket sorolja fel.
Átirányítást tartalmazó oldal:
Az oldal átirányít egy másik URL-re, ezért a Google nem indexeli az eredeti oldalt.
Feltérképezve – jelenleg nincs indexelve:
Az oldalt a Google feltérképezte, de valamilyen okból kifolyólag nem indexelte. Pl. lehet, hogy nem találta elég értékesnek, vagy már indexelt hasonló tartalmú oldalt.
Felfedezve – jelenleg nincs indexelve:
Az URL-t a Google felfedezte, de még nem térképezte fel, és nem is indexelte. Ha fontosak ezek az URL-ek, akkor érdemes lehet közvetlenül is beküldeni a Google-nek, vagy több oldalról (különösen a főoldalról) hivatkozni erre az aloldalra.
Ezek az okok segíthetnek megérteni, miért nem jelenik meg egy oldal a keresési találatok között, és lehetőséget adnak arra, hogy megfelelően optimalizáljuk weboldalunk technikai felépítését a jobb indexálhatóság érdekében.
Konkrét URL vizsgálata
A Search Console-ban lehetőségünk van arra is, hogy felül beírva egy adott URL-t, meg tudjuk nézni, miként kezeli azt a Google:
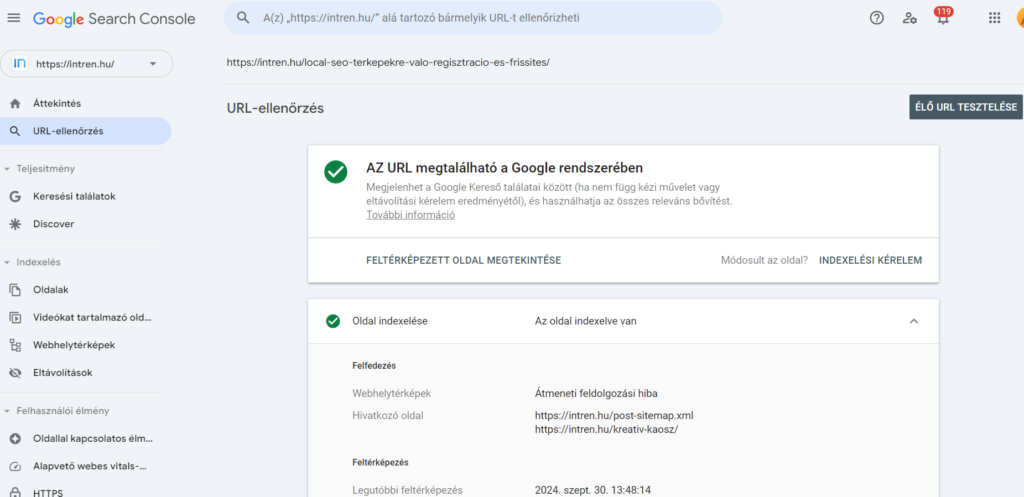
A https://intren.hu/local-seo-terkepekre-valo-regisztracio-es-frissites/ URL-t beírva láthatjuk, hogy a Google indexelte a keresőben, megtalálható ott.
Továbbá azt is kijelzi, hogy melyik oldaltérképben találta meg a linket, illetve ha talál hivatkozó oldalt, abból is betesz 1-2 példát. Valamint látszik a legutóbbi feltérképezés ideje is. Amennyiben már régen térképezte fel és változott a tartalma/nem indexelte, akkor itt az “indexelési kérelem” gombra kattintva lehet felgyorsítani, hogy újra megvizsgálja az oldalt.
Több ezer URL vizsgálata egyszerre ScreamingFrog-al
A ScreamingFrog fizetős verziójában számos más programmal is össze lehet kötni a szoftvert:
- Google Search Console
- Google Analytics
- Ahrefs
- PageSpeed Insights
- Majestic
- Moz
Nekünk az elemzéshez a Google Search Console-al kell összekötnünk.
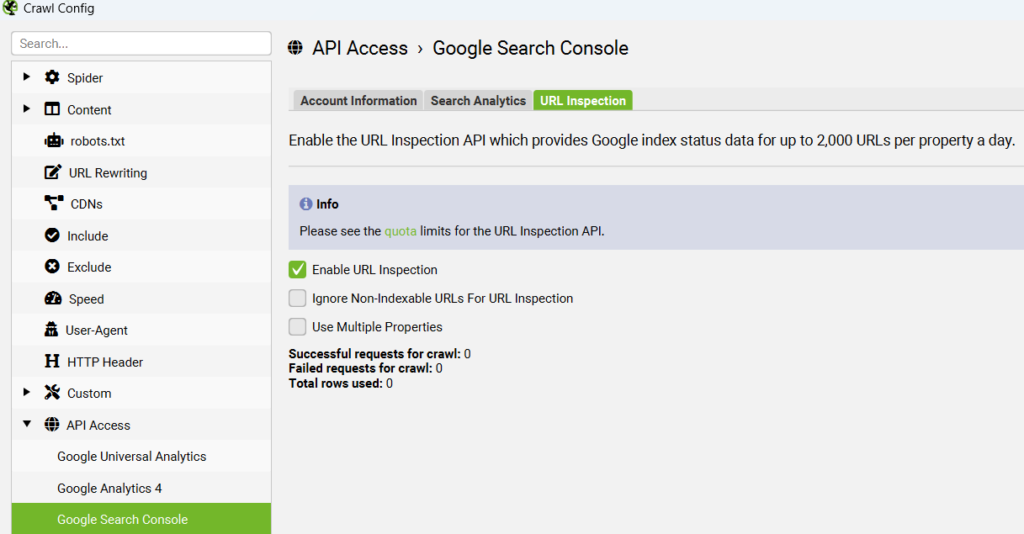
Összekötés után az “URL Inspection” fülön tudjuk bekapcsolni ezt a funkciót.
Alapból napi 2000 URL-t vizsgálhatunk ezzel, de ha van Domain és URL szintű hozzáférésünk is az oldalhoz a Search Console-ban, akkor ez 4000-re növelhető.
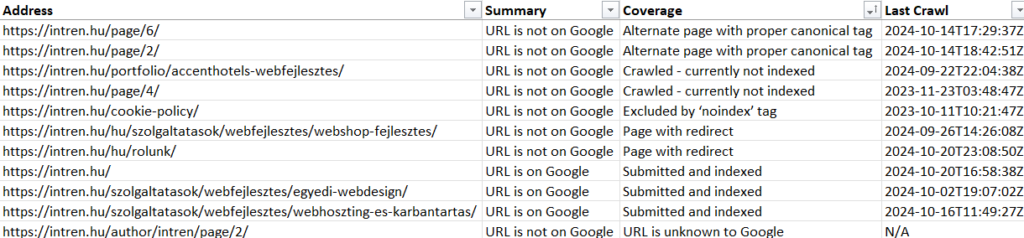
Miután lefuttattuk a crawl-t, URL szinten is láthatjuk, hogy benne van-e a Google indexébe, és ha nincs miért. Továbbá az is látszik itt, hogy egy “Noindex”-el kitiltott oldalt 1 évvel ezelőtt nézett meg utoljára.
Duplikációk esetén pedig látható, hogy mit indexált be helyette a Google, miket gondol duplikált tartalmaknak.
A Google Search Console és a ScreamingFrog olyan eszközök, amelyek segítenek az oldalak indexelésének nyomon követésében, valamint az esetleges hibák azonosításában és javításában. Fontos időnként felülvizsgálni az indexelési beállításokat, hogy biztosak legyünk abban, hogy az oldalak megfelelően elérhetőek a keresőmotorok számára.
Ha Önnek is szüksége lenne egy ilyen vizsgálatra, vagy egy átfogóbb SEO Auditra, keressen minket bátran, és segítünk optimalizálni weboldala indexelhetőségét és láthatóságát a keresőkben!